File Systems
We have been focusing on CPU and Memory which are the heart of a computer system. But there are many other devices our CPU memory interface with.
- Harddrives
- SSD
- Keyboard/Mouse
- Graphics
- Sound
- Network
- USB devices
How do we connect these devices to the system ?
What is the general protocol we have for communicating with them ?
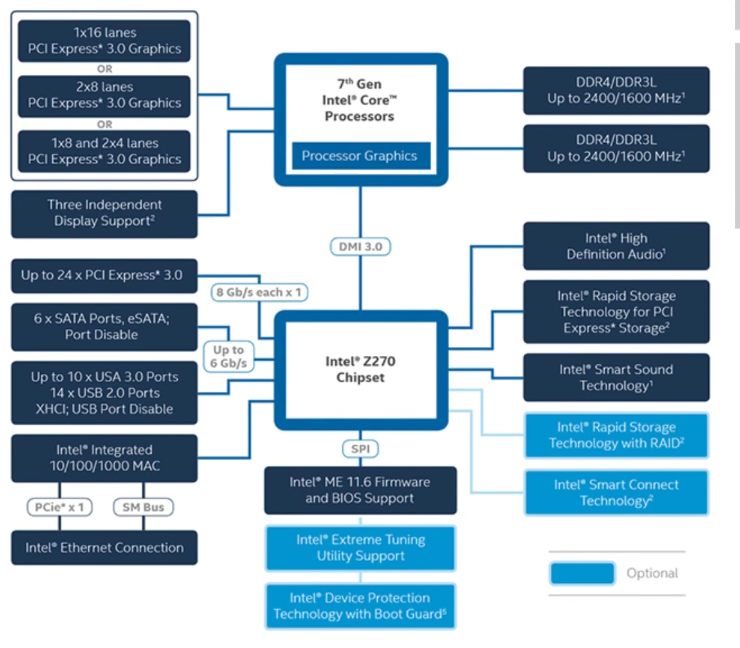
Every device has an interface that it presents to the CPU. The CPU accesses the interface to ask the device to perform some action.
A device Controllers is a piece of hardware that presents a device interface which implements the device functionality.
A generic device interface has a few different standard parts
- Data Register <-> transferring data to and from device
- Command Register (read, write and flush) send commands to the Device.
- Status Register (busy, error, free)
Naive Generic Device Communication Protocol:
CPU communicates with controller
- Check if device is available. If busy wait. while(status == busy); // wait for device
- If available give command, by writing data to data register and then write command to command register. Once we write the command to the command register the device controller knows the data is alread in the data register and starts processing.
- Wait for the operation to completion. while(status == busy); // wait for device.
What is ineffecient about the Naive Communiation protocol ?
- Cpu wasting alot of cpu cylce waiting for device. in the previous model the CPU keeps checking the device status over and over again till device is ready. This is called Polling. This maybe ok for a super fast device. But hardrives are super slow compared to CPU.
- Cpu is exchanging data with the device via registers on the controller which may only be 1-4 bytes wide. If 100mb bytes needs to be transferred that could be 100 million cylces of cpu time to xfer the data.Very expensive.
How do we avoid the ineffiecency of polling the device status registers? We give the controller the ability to trigger an interupt on the cpu.
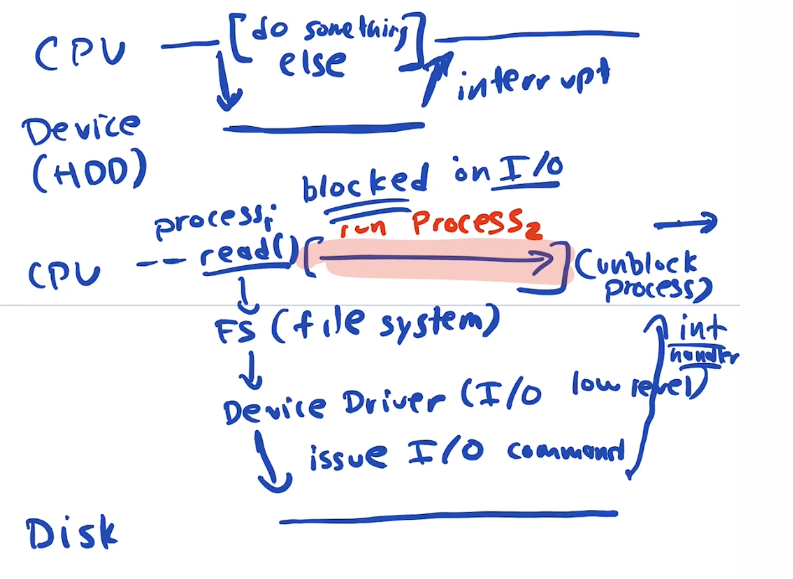
How do we take the work load off of the CPU for transferring data from memory to data registers on the device? We add specialized hardware, called Direct Memory Access controller. DMA read/writes directly from ram to/from device controller data register. Handles all copies.
CPU must change page settings to protect data prior to transfer the data doesn't change mid copy. This is calling pinning the page.
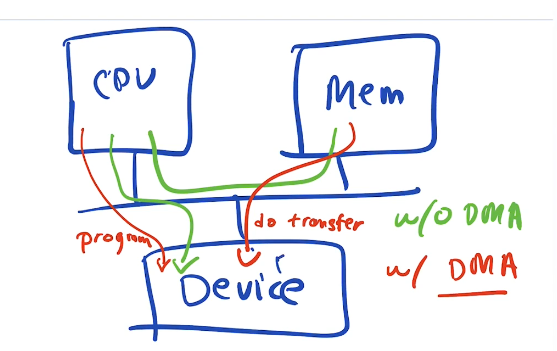
There are two ways a CPU can interact with device controller
- CPU Uses special I/O instructions built into the CPU
- More Modern way is Memory mapped I/O, registers of the controller are mapped into memory as regular addresses, so cpu can just write to those addresses in memory like it would to any address in ram.
Hard Drives
A hard drive is a PERSISTENT STORAGE DEVICE. Means when power gets shut off bits are preserved and come back when power comes back on.
How do we design an OS to use HD effeciently, speed ? power ?
Let's build an abstract model of a HD from a CS perspective.
hard drive components- Electronic Parts: A controller that exports the interface and controls the operation of each request. The controller is sophisticated it could be running hundreds of thousands lines of code within it..
- Mechanical Parts: platters, arms, motors
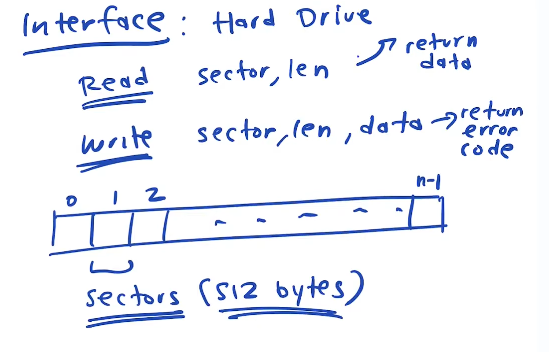
The interface to harddrive is very similiar to interface to memory. It is just a storage device that you can read from, or write to.
The interface presents the hard drive as a series of numbered sectors, each sector holds 512 bytes. Each sector has an address. When we want to read or write we issue a read or write command read(sector address, length) or write (sector address, length, data)
The internals of a harddrive
The platters: A HD is made up of one or more hard metal platters which are magentacally coated on both sides. Each platter has a dedicated read write head that can move back and forth, just like a record play. The platters are all connected to the same motor spinning at the same speed.
The Data is organized into tracks. Just like a song on an LP. Each track is divided into 512 byte sectors, as mentioned previously.
The controller needs to know which sector is on which track and on which platter.
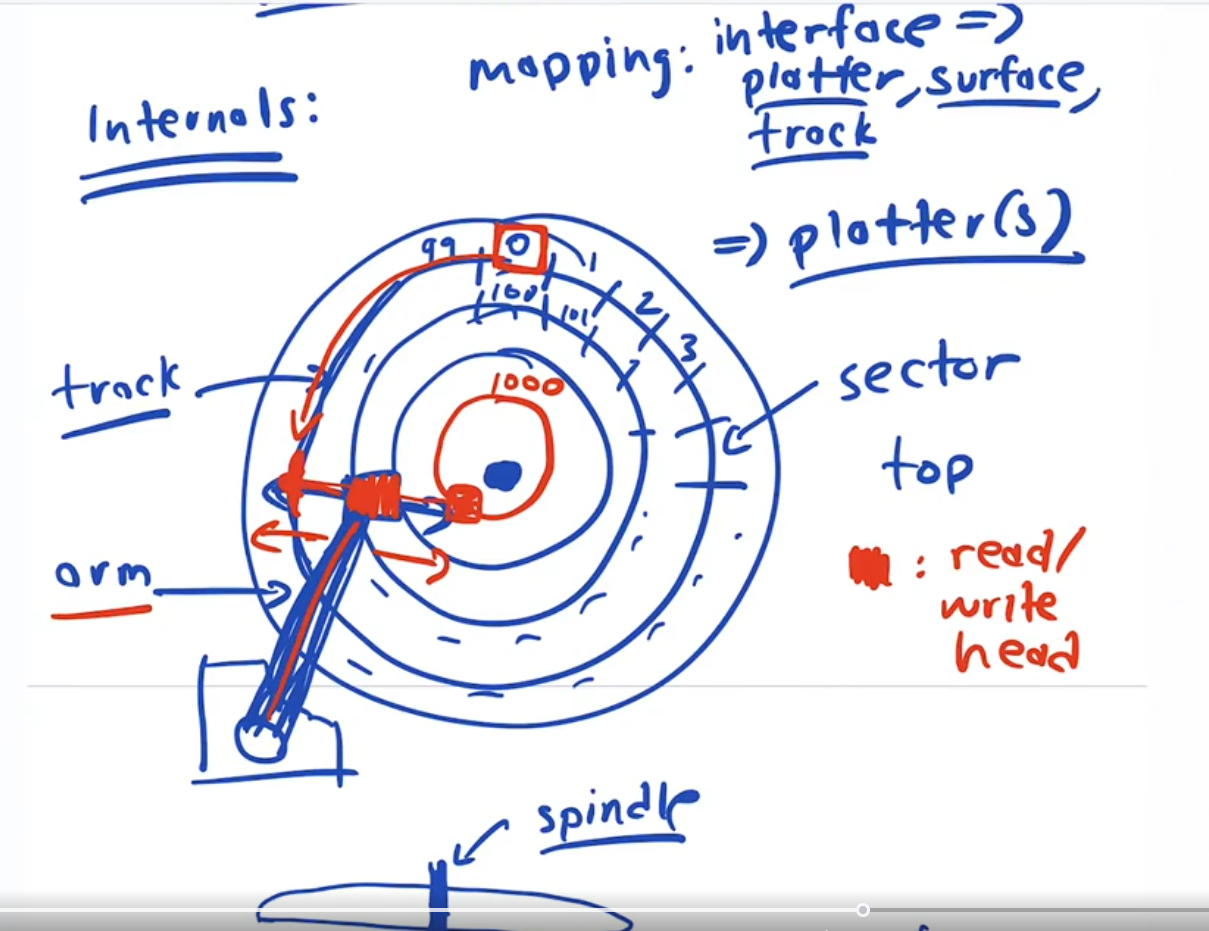
Each side of each platter has a dedicated head. heads move all together and only one sector is read or writen at a time.
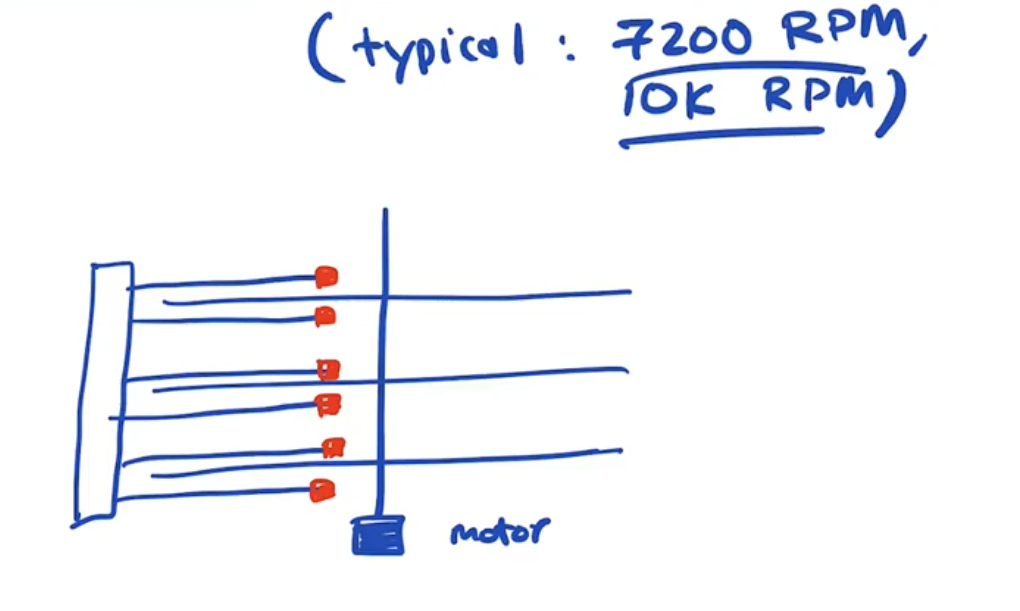
There are 3 component actions involved in read/write
- Seek: Move the arm so the head is at the correct track. This must be very precise, you can fit hundreds of tracks on the width of a human hair. How does the head know it is on the correct track? the HD is going to encode some location information directly into every track, so the head can read which track it is on at any given moment.
- Rotational Delay: Waiting for desired sector to rotate under the head
- Transfer: Do the read or write.
A hard drive is a Random Access device, but if things are far away from each other it can take along time to move the heads to the write postiion.
In a poorly designed system. There can be alot of OVERHEAD during SEEK and ROTATION. If you are reading and writing small chunks of data you will incur Seek and rotate costs if the head has to move for each small chunk. If the head can stay on a single track and ready lots of sectors in a row it will reduce the cost of seek and rotate.
Given: T(i/o) = T(seek) + T(Rotate) + T(Transfer)
- T(Transfer) 100 Mb/s
- T(seek): 7ms
- T(rotattion 10k rpm drivex): 3ms
How long does it take to transfer 1mb using the constants if we only have to move the arm once to read 1mb?
T(i/o) = 7ms(seek) + 3ms(rotate) + 10ms (@100mb/s transer) = 1mb/20ms = 50mb/sec (notice this is 50% of our transfer rate)
In this case 50% of the time is spent seeking and rotating(10ms) the other 50% is transferring(10ms)
What if we have do tiny little i/o's (1kb) for every arm movement using the same constants as above.
Transfer time @100mb/s for 1kb is essentially 0. but we still have to use 10ms for seek and rotate.
1kb/10ms = 100kb/second = .1Mb/sec
OMG!! our previous example had 50Mb/sec throughput
As you can see how the data is distributed across the disks is crucial to effeincy. We have to make a very concerted effort to group block of data into large chunks together to minimize seek and rotate overhead.
I/O scheduling
Given a set of I/O requests how do we decide which to do first if our goal is performance?
The nature of an I/O job is different than a scheduling the CPU. With a CPU scheduler we don't know much about the jobs we are running. With an I/O requests, with certain knowledge of disk arm location we can predict how long a job will take. We may be know the length of the job.
Remember in our chapters on CPU scheduling, shortest job first was the most effecient alogrithm. Because we know more about I/O jobs we can potentially use SJF.
At the OS level harddrive internals are hidden.We are just giving commands to read block 0, write block 1000, etc...
Inside the drive we have much more knowledge
Modern I/0 devices allow the OS to issue many requests to them and the device knowing it's internals can do the externals
Read the section on harddrive scheduling and HAPPY THNKSGIVING.
RAID systems
The purpose of a harddrive is persistence storage. But harddrives can fail so if we really want to ensure the persistence of data, we have to make multiple copies of it.
Modern Data centers, facebook, google, amazon, snapchat, tiktok replicate the data on their servers across data centers across the world, to ensure persistence.
Hard drives are very slow but cheap, and that's why they are still around.
Operations on harddrives are on the order of milliseconds while cpu is on the order of nano seconds, harddrives are 1 MILLION times slower than cpu's. Meaning.
It takes 1 million times longer to write 512 bytes on a hard drive compared to writing 512 bytes in ram.
If you are trying to write high performance systems. You try and AVOID doing IO as much as possible. Load as much into ram as possible in one shot.
It is always fastest to do the larges possible read and writes with data stored sequentially
RAID: Redundant array of independent disks
Raid uses many drives not one. Here's why
- Performance -> We can make IO faster by using many drives in paralled at once which creates more throughput more IO per second
- Reliablility -> hardrives can fail because of all the moving parts. By keeping many copies of things we can tolerate failures and keep running
- Capacity -> more space
There are different raid types each of which emphasize each of these characterstics
Raid Interface
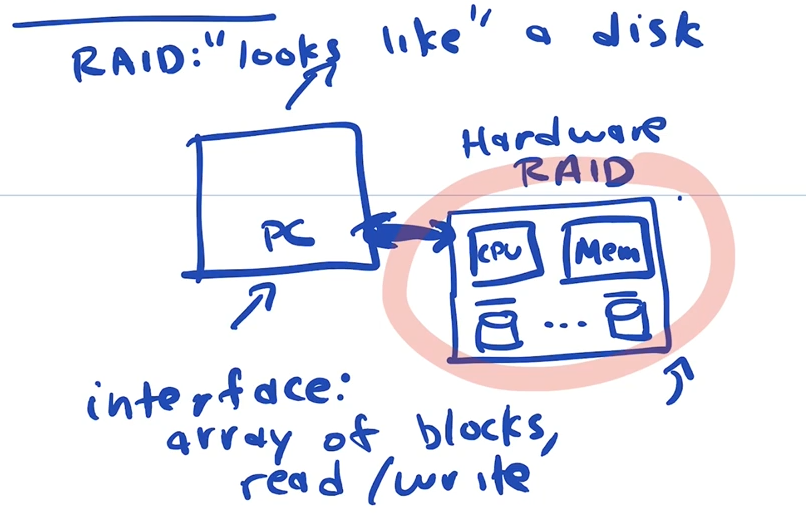
A hardware RAID is a physical device with some number of harddrives in it that presents itself as a single harddrive to the OS. It hides the fact that it is mulitple Drives running in parrallel.
- The computer connects to the device just like it would to a regular hard disk.
- To the computer the entire RAID system creates an interface as if it was a single disk.
Becuase it is made up of multiple drives it can present as having more effeciecny in the different characterstics than a single drive.
To the OS it looks just like an array of blocks that it can read or write.
To a computer a A Raid device just presents the interface of a single HD. But Notice if you look at what's in a Raid device it looks just like a computer. It has memory, a cpu and multiple hard disks.
Fault Model: how do we expect hard drives to fail, and how do we build a systemb on top of that ?
Lets make some very simplified assumptions about what it means for a drive to fail
- There are 2 states for the drives: broken or working
- It's easy to detect if they are broken or not.
In reality there are many other complicated and potential failures.
There are different types of raid, called raid levels. Each implement a different strategy managing redundant arrays of independent disks
There are levels 0,1,2,3,4,5,6 We will be talking about levels 0, 1, 4, 5.
- Level 0: Striping with no redundancy
- level 1: Mirroring, keeping n copies of things n > 1
- level 4,5: Parity Based, use a compact form of redundancy with some performance loss
Metrics:
- Spped
- Reliablity
- Capacity
With any raid we have some number of hard drives. The interface to a HD just looks like an linear array of blocks(sectors). We are doing reads and writes to the array of blocks and need to map them to the disks themselves. Which is similiar to Virtual Memory. We have to take a interface address and map it onto a particuliar physical disk and an offset into that disk.
Raid level 0: striping
striping maps addresses sequentially across the drives, each next address is on the next drive.
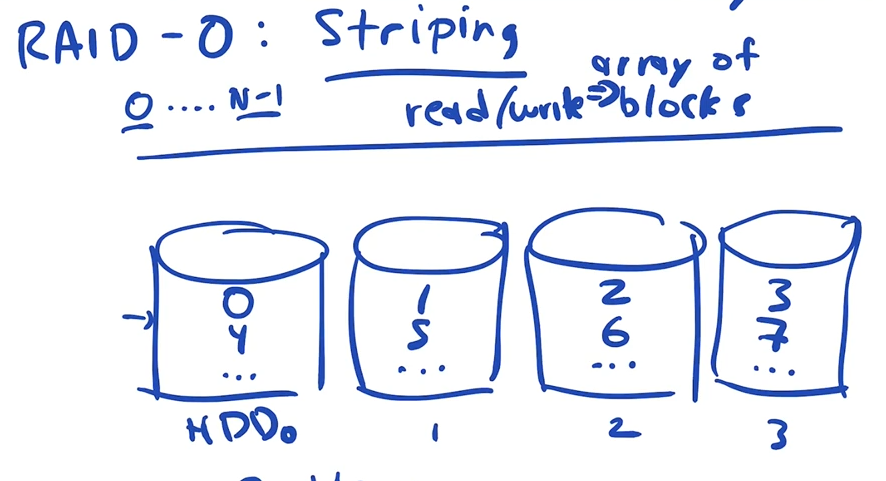
To translate from Interface Address => Disk address(HD_number:Offset)
- HD number = (interface address) % (number of disks)
- Offset = (interface address) / (number of disks)
So if we had 4 disks labeled 0 - 3 and we wanted interface address 100 it would be offset 25 on disk 0.
this is a static mapping
Striping Metric Evaluations
- Reliability: "BAD" No redundancy. 0 tolerance for failure, worse than a single drive because more drives have higher probablilty of failing
- Capacity: "Exceeletn" . If we have N disks and each had d bytes of capacity than total capacity is n * d. We have full capacity, the total combination of all the disks. This is because no redundancy of data
- Performance: We need to evaluate based on whether we are reading or writing, and whether we are accessing using large sequential requests or small random requests. HD read and write approx same speed. SSD read much faster than writing.
RAID 0 is highest level of performance of any raid or single drive.
Sequential large read/write. Given N disks with the ability to read/write at S MB/s our bandwidth will be N * S, In this case we are using all the disks in parralel. We have the power is parallelism
Random small read/write. Each disk with have a bandwidth of R MB/s where R is much less than S just as we saw last lecture, but we still have parrallelism so still faster than single drive
Striping is great for performance and capacity but you don't get any reliability. The more drives you have the more likely one is going to fail.
Raid level 1: Mirroring
for each logical block of data we will keep 2 physical copies
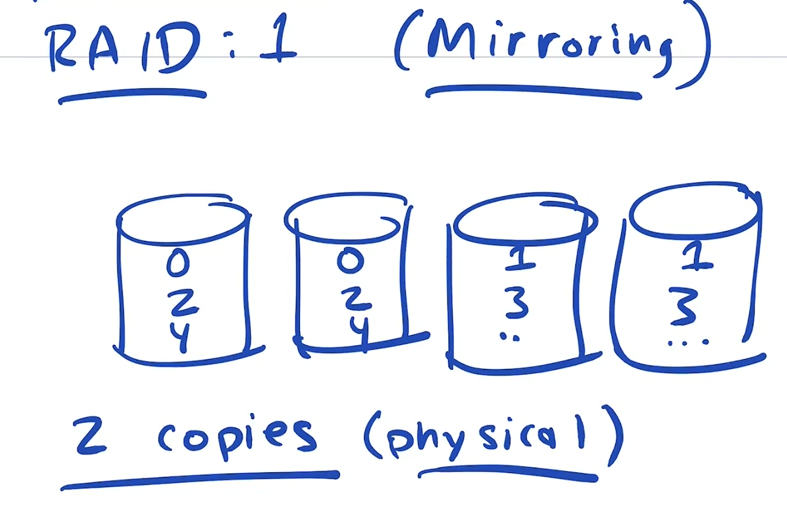
Capacity: given N drives and D bytes per drive, our capcity (N*D)/2 bytes
Mirroring Reliability
Given our fault model, where a whole drive fails. How many failures can we tolerate?
We can tolerate 2 failures, if it is the correct drives that fail, but to be safe we should replace drives when 1 fails.
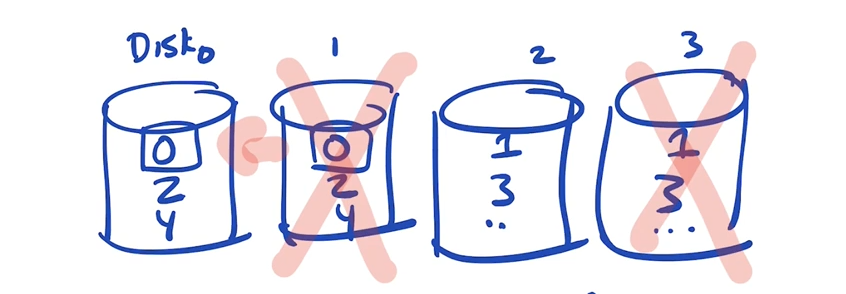
Raid 1: performance
- Random I/O-writes: Is a little slower than writing to a single drive because you have to wait until the heads on BOTH drive seek and rotate.
- Random I/O-reads: we only read from one drive at a time. this takes the same time as reading from a single drive.
FILE SYSTEMS
What is a file ?
A classic unix file is an array of bytes stored on a disk.
You can read/write create and delete files
attributes that the os stores regarding files
- Each file hs a low-level name => which is just a number
- File Size
- Permissions
- created,last Modifies and last accessed times
- location on the disk (block address)where the file lives
What is a directory?
They are specific type of file.
Directories are array of records, each record is the human readable name => mapped to a low level name(which is just a number) That number is called an inode number.
Files and Dirs are arranged in a tree structure, with a root. In Unix the root is named "/" (forward slash)
File System API
Files are managed using system calls. the commone pattern, is open, (read|write), (read|write), close
- int creat(const char *pathname, mode_t mode);
- int open(const char *pathname, int flags); returns a file descriptor(int)
- ssize_t read(int fd, void *buf, size_t count);
- ssize_t write(int fd, const void *buf, size_t count);
- int close(int fd);
For each process, the OS mantains a "descriptor table", which is an array with a bunch of entries. The file descriptor returned by open is an index into this table Each entry in the table is apointer to a struct.
The struct that is being pointed to is apart of a system wide table that is a list of all files opened by all processess
the struct keeps track of
- what type of file it is, ie reg file
- read write permissions to the file
- an OFFSET, keeps track of the next byte to read or write. every time you read offset advances.
what happesn when we delete a file
we use the system call unlink
int unlinkat(int dirfd, const char *pathname, int flags);
Why is it called unlink?
what happens when we rename a file using the mv command, what is being changed?
stat command gives us some information being stored about a file
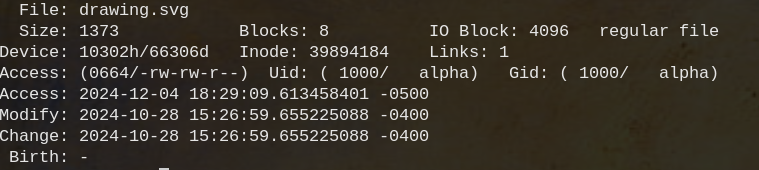
when we just create a file it has 0 blocks and size 0

After we just echo one byte to the file we have allocated 8 blocks 32k?
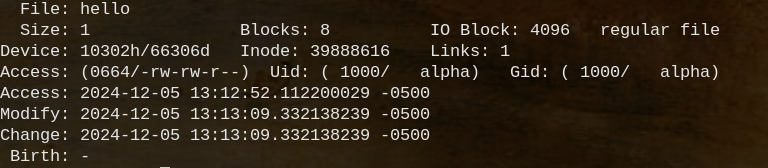
a DIRECTORY is a table where col-1 is the human readable name of a file and col 2 is the inode number of the file, the indoe is a struct that holds information about the file.
Each row of the table is a different file.
There are several syscalls that interface directories.
- int mkdirat(int dirfd, const char *pathname, mode_t mode); make a directory
- int rmdir(const char *pathname);remove a directory
- int readdir(unsigned int fd, struct old_linux_dirent *dirp, unsigned int count); read a directory
You can't write to a directory. Directories are only written automatically when files are created. ls -i shows the directory table as specified above.
In a single directory we have a low level name that maps to an inode number
But to access files we use PATHNAMES. There are different kinds of pathnames
Absolute pathnames start at the root of the directory tree.
Opening a file requires a path traversal down the directory tree
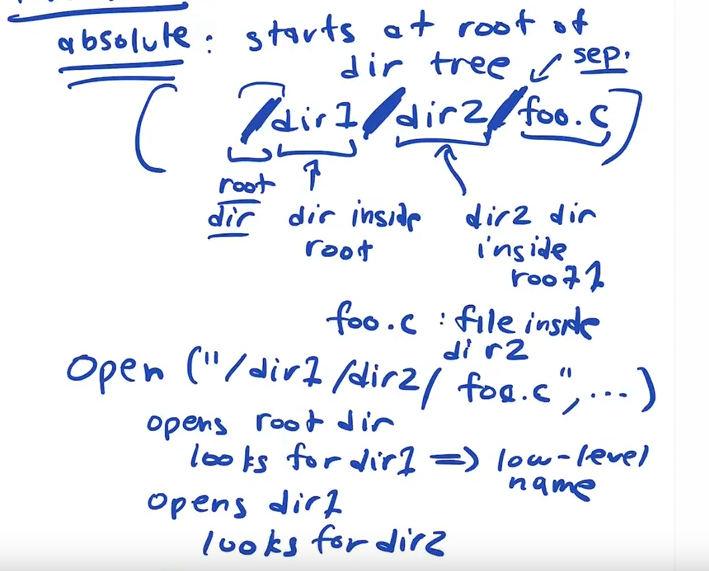
relative path names start the traversal at the current working directory "." or from the parent directory "../"
notice every directory listing has a "./" and "../" listed in them
~ is interpreted by the shell to
There are also hardlinks ie: "ln file1 file2" will set file1 to map to the same inode number as file 2.
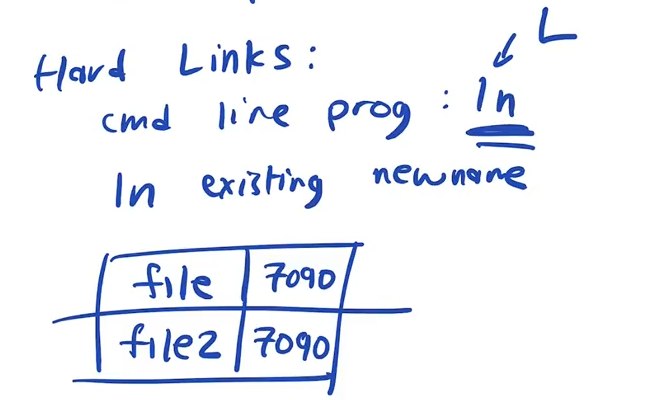
Now when we can see what happens when we remove a file using rm.
When we remove a file we are just removing the entry from a directory
We use the unlink syscall because we are unlinking the human readable lowlevel name from the inode number
Once an inode has no more human readable names linked to it, all the blocks are released and it is removed from the file system
File system implementations
Our abstraction into the file sytems is Files and Directories.
A file just an array of bytes and operations we can do on them, create, open ,read ,write, unlink, close
A directory is a way of organizing files and other direcotories, it is a list of mappings from human readable filename to inode number.
A directory can contain entries for regular files or other directories. That forms a hierarchy of directories called the file sytem tree. The tree starts at root "/".
In order to understand the file systme implementations we need understand "on disk data structures"
We need to understand access methods to interact with those data structures.
The very simple file system
The file system has an api. That api takes calls like read,write etc at the top and shoots out instructions to read and write the actual blocks on the disk.
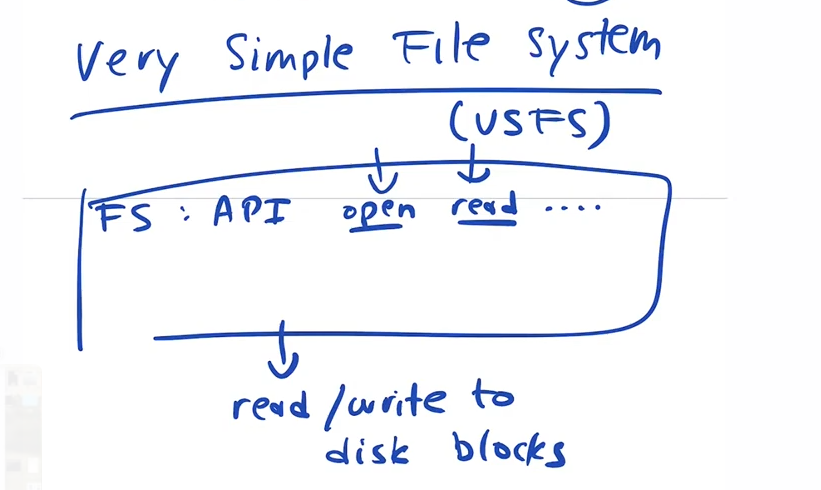
How are those disk blocks structured ? Each block is made up of x number of 512b sectors
The disk is just a bunch of blocks numbered from 0 to max size. the file system has to map all the files and directories on those blocks
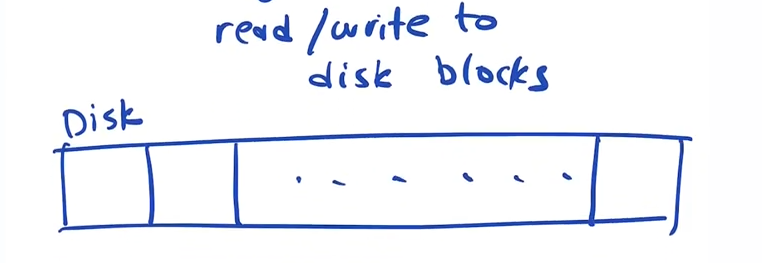
What info needs to be on disk?
In our "very simple file system" we separate some contigous part of the disk from block n to xn to be used to store data. Data in this case is files and directories
Block size
Block size must be a multiple of sector size.
A block is minimial unit of disk allocation for a file or directory
What are the trade offs when we have larger vs smaller blocks ?
Large blocks
- Disks read congitugous data more effeciently so if you have one large block to store a large file it will be very effecient.
- when we have large blocks we need less metadata stored to manage blocks
- Large blocks will have lots of internal waste, internal fragmentations
small blocks
- Less internal waste and fragmentation
- large files could be spread across many blocks that you need to keep track of.
So we carve off most of the disk for blocks that will be storing data.
we carve off another small portion of the disk to store information about each file. This area is divided into an array of structures that contain information for each file. These structure are called inodes. AN INODE NUMBER, which is it's lowlevel name, IS AN INDEX INTO THE ARRAY. It is called the inode table. It is a fixed size array of possible inodes
The inode structure stores
- type
- ownership
- permissions
- Time stamps
- number of blocks allocated to this file/dir
- POINTERS TO THE BLOCKS OF THIS FILE/DIR
Given an inode number you locate it on disk, by knowing the the base adddress of the inode array and the size of each inode.
We also need to track which blocks are free and which have been allocated for both the inode table area and the data area
We carve off block 1 and block 2 of the disk to be used for an Inode bitmap and Data bitmap respectively. Each bit specifies wether an inode is free or in use in the inode table, or whether a block is free or in use in the data section of the drive.
When we first access the file system,
Block is 0 is called the SUPER BLOCK, it contains all the system wide file system information
- Block size
- File system type
- inode table base address
- data blocks base address
- etc