Timeline review
- @boot time OS runs first. The CPU starts in Privilged/kernel mode
- Using priveleges instructions the OS setups up all excpetions/trap and interupt handlers routines so cpu knows where they are in memory. Handlers are just code.
- OS starts a timer interrupt(using a priveleged instruction) os it will have cpu control at certain time intervals
- Once all that is done, OS is ready to run a user program
interactions: OS service
- OS starts kernel mode(sets everything up)
- Set cpu to user mode and run program A
- Program A wants service so it makes a system call (trap instruction).
Some system calls maybe request for file i/o, create a new process using fork/exec, exit, wait,network i/o, etc...
- In a Trap instruction, The CPU transitions itself from user mode to kernel mode, and jumps into the os at the predetermined trap handlers address. This all happens in the hardware, the User code does not do any of this.
- The CPU must also save the register state of the running process so we can resume execution later.
Return from trap
When the OS is done handling the trap, we return to the running program using the return from trap instruction, In the return from trap, The registers are restored and the cpu sets itself back to user mode. The $rip will be pointing to the next instruction to execute and cpu will continue
Even when we start a program for the first time, the OS uses a return from trap instruction. The OS will set the $rip to the main entry point and call return from trap.
What happens if program A doesnt ever cause an exception or trap How does the OS regain control?
- OS starts kernel mode(sets everything up) including timer
- Set cpu to user mode and run program A, infinite loop
- A timer interupt is set in cpu, the os handler runs
- The handler can choose whether to keep running Program A or switch out to Program B, this is known as a CONTEXT SWITCH
- OS calls return from trap to the program it chooses
Process List
OS must keep track of all processes running on the system. Each process will have a bunch of info associated with it in some kind of Data Structure, and the OS will keep a linked list, tree or array of all processes on the system
Process State
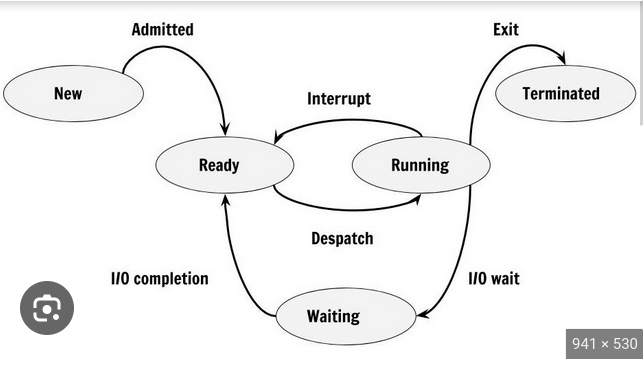
OS must keep track of process state. A process can be in one of several state.
- READY: Many processes can be in this state at a given time they are waiting to be run.
- RUNNING: only one process is running at a time.
- BLOCKED:
Some operations like i/o are very slow compared to processor speed. If a process is waiting for some slow operation, it gets placed in a block state
OS chooses on interrupt
When the interupt timer occurs the OS can go thru the process list and see which processes are READY and then decide which one to put into RUNNING state.
Blocked Processes timeline
If you imagine process A running on the cpu, it calls a trap to read from disk. considering a cpu cycle is .3 nano seconds and reading from disk is 10 m/s, if the cpu did not move the process A into a BLOCKED state, it could potentially waste thousands of cpu cycles. CPU utilization must be optimized. We need to keep process A out of the CUE of READY processes cue until the i/o is done.
OS scheduling policy
We now have the mechanism we can use to switch processes. Now we need to make decisions about which process to run and when.
CPU Scheduler
What we have been speaking about is the mechanism portion of the LIMITED DIRECT EXECTUTION protocol. Now we will move on to understanding the polices a process scheduler may use to decide which process to run next. The scheduler is the part of the OS that implements policies regarding when to switch processes on and off the CPU.
some idealised (unrealistic) Assumptions used for scheduler design and evaluation
- When we schedule processes, we call them jobs. This terminology comes from the days of how to schedule work in a factory for efficiency.
- We have a SET of jobs
- They all arrive at the same time in the ready state
- Each Job only needs the CPU(no i/o)
- Each jobs will run for some T(i) amount of time
- T(i) is the same for all processes, T(i) is known ahead of time
Metrics
We need a metric to use to determine which policy works the best. The first metric we are going to use is called T(avg) average turnaround time. (time the job ended) - (time arrived in system)
Algorithm 1: FIFO, first come first serve
Given JOBS: A, B, C all arrive at T = 0
If each takes 100 time units to complete and we run each to completion.
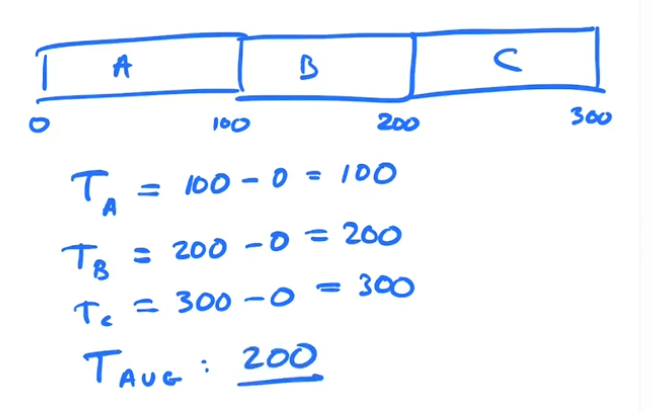
Lets change some assumptions
run time for each process T(i) we said was the same for all of our job in the previous set of assumptions
Now lets assume t(i)runtime is different for each job
We want to think adversarily, so what runtimes would we assign to A,B,C to make FIFO very bad ?
If you make T(A) = 100, T(B) = 10, T(C) = 10, you will notice certain properteis, It seems to make sense to run the shortest job first!!
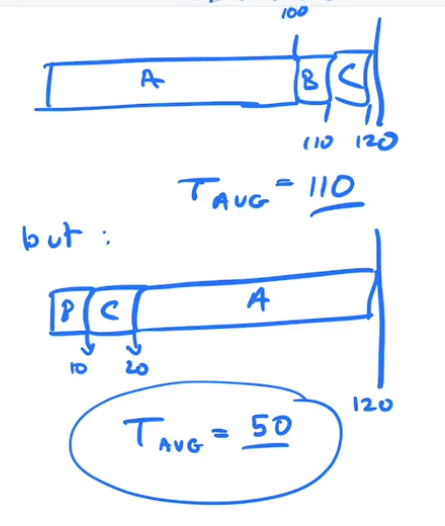
Algorithm 2: Shortest Job First
If you have a bunch of jobs to do and care about the turnaround time of each, schedule the shortest one first
If we go with our current assumptions that all jobs arrive at the same time with different T(i) SJF will give the fastest average turnaround time.
If we change the assumption to one where jobs arrive at different times?
If a job that A is running and Job is comes in, what do we do if the time remaining to finish A Tr(A) is longer than T(B)? We can generalize SJF to next another alogrithm: STCF (shortest time to completion first)

New Metric: Response Time
(Time Process first runs) - (Time it arrives)
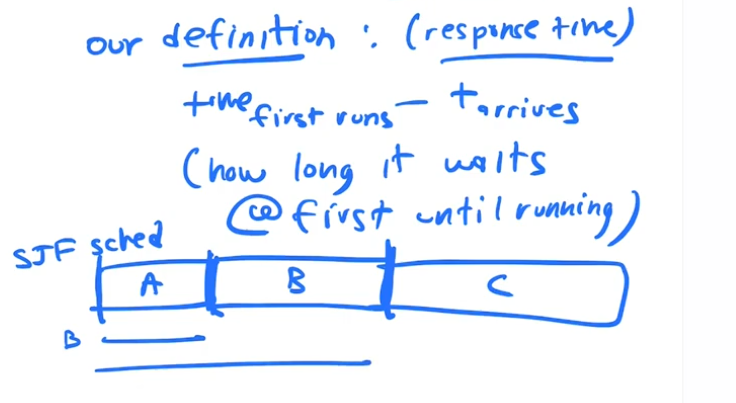
SJF is a very effecient algorithm for our first metric, T(AVG) turnaround time. But is not that good for Response Time.
What policy should we use to minimize Response Time?
Round Robin Scheduling
Minimizes Response Time.
Run a little slice of A, then a Slice of B then slice of C. and continue rotating the jobs on the cpu. That slice is often called a quantum, or a timeslice. It is some multiple of our timer interupt period.
Tradeoffs: if we have short timeslice we have better response time, but incur high context switch overhead. Longer timeslice have worse response time, but are more efficient because of fewer context switches.

We would like to use "shortest job first" or "shortest job(time) to completion first", because the average turn around time is quickest in these algorithms. But it assumes knowledge of actual "total and remaining run time" of every job. We DONT ACTUALY KNOW how long a job is going to run for so we can't actually use these algorithms.
The two metrics we are looking at are
- Turnaround Time, which is the time span from job arrival to job completion
- Response time which is time span from job arrival to job start running
To optimize the this metric we came up with round robin scheduling, using a timeslice(quantum), that is some multiple of our timer interrupt, to switch between jobs. Turnaround time is not that good in round robin scheduling.
A Real Scheduling Policy
To make a Real scheduler, we can't make any unrealistic assumptions
We call our real scheduler a "MULTI LEVEL FEEDBACK QUEUE". It is a general principal approach to building an OS Scheduler.
Central Problem of Most OS policies
The OS doesn't really know very much about running processes! It doesn't know what is going to run, when, for how long, etc...
The OS would like to learn which jobs are shorter, which are long running
HOW CAN THE OS Learn the nature of JOBS?
How do you manage your own scheduling. How do you know how long something is going to take when you are planning your day or week?
Use the past to predict the future
The OS needs to take measurements of current jobs that are RUNNING to understand, characteristics of those jobs. It is essentialy learning from the past to predict the future. This is the basis of anything that learns, just like a machine learning algorithm does.
The OS uses recent behavior to predict the near future. All policies of the OS us this basic premise
Measurements
The OS can keep statistics about running processes
- how long has it been running
- how many i/o calls did it make
Multi level feed back queue
- The MLFQ has many queues
- Job is only on one queue at any given time
- each queue is assigned a priority level
- OS follows rules regarding jobs on queues

Rules
- If Priority of Job A is Higher than priority of Job B, then A runs and B doesn't.
- If 2 JOBS B and C have the same Priority, then Round Robin between them
- Start every new process at the highest priority
- If a job uses a time slice up at a given priority, then at the end of time slice move down it down one priority level

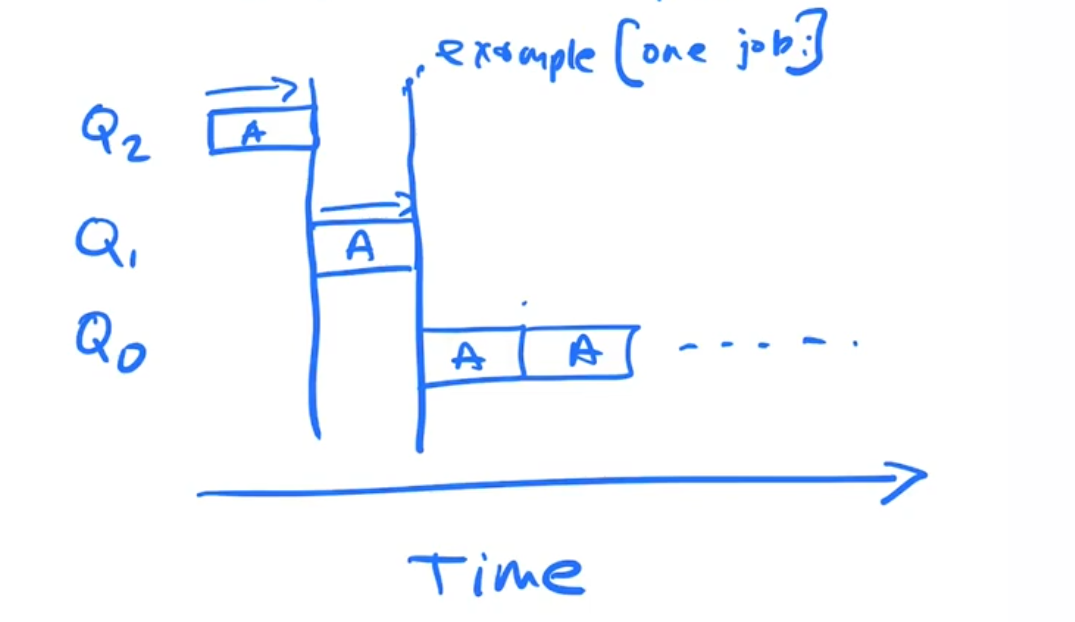
Example 1, Single Job
Given Job A and Q's Q2, Q1, Q0 where highest priority is highest Q number
- Job A starts off on Q2 and starts runnging
- After some quantum period, when an interrupt occurs off A get moved to Q1 and runs becaust there are no other jobs
- Aftes some quantum period, when and interupt occurs A gets move to Q0 and runs because there are no other jobs
- A keeps running on Q0 till complete
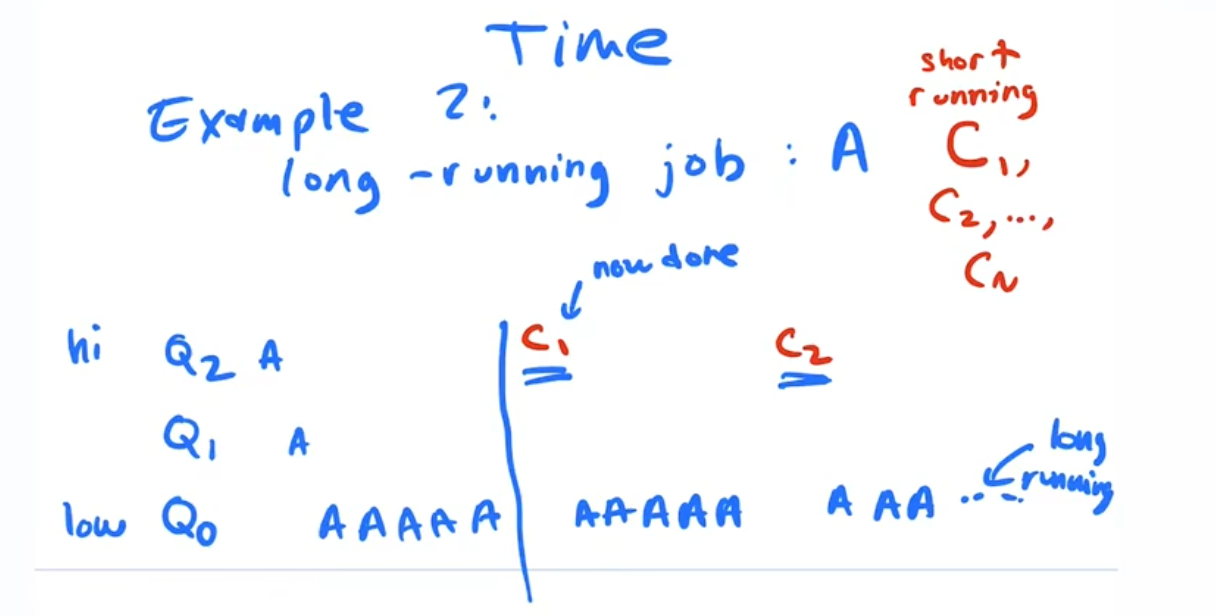
Example 2, Two jobs, A is long running and C is a short Job
- Job A comes in first and A goes thru the cycle described in example 1, runs and trickles down to Q0
- Job C1 enters the system on Q2, runs and completes because it is a short running job
- Job A on q0 runs
- Job C2 enters the systmes on Q2, runs and completes becaust it is a short running job
- Job A on q0 runs
Adversarial thinking
So far we see that our MultiLevel Feedback queue allows long jobs to run and eventually complete while quickly addressing the needs of short jobs.
If you are a bad actor on the previous system you can just flood the system with short process c1,c2,c3,..,cn then job A(long running jobs) will never run
This is called "the starvation problem". All schedulers need to consider this scenario to ensure long running jobs make progress
To solve this problem, eventually long running jobs need to move up in priority
NEW RULE: Every T seconds move all jobs to highest priority queue
Learning reset
by moving all jobs back to high priority, we give the OS an opportunity to reset it's learning and reavaluate it's understanding of the job periodiclly
This allows the OS Policy take changes in the nature of jobs into consideration.
Some jobs may be doing "BATCH" processing, which is spending time doing computations in the bakcground and some jobs may be in more of an "INTERACTIVE" mode where they are interacting with a user.
Jobs may change back and forth between these modes of operating
recap
- Jobs come in and are on high priority q
- As jobs are serviced they move down in priority
- This allows short jobs to be immediately serviced
- Long running jobs move to the lowest priority over time.
- We make sure long runnign jobs are not starved by periodiclly bumping them back to the top.
How do we handle jobs that are waiting for i/o
we would like to keep the cpu busy while a job is waiting for i/o

How do we handle a job that is in one of our queues and does does some i/o?
I/O job (Naive) rule
RULE: IF a job runs and it calls for a i/o before a timeslice has expired, leave it at the same priority level.
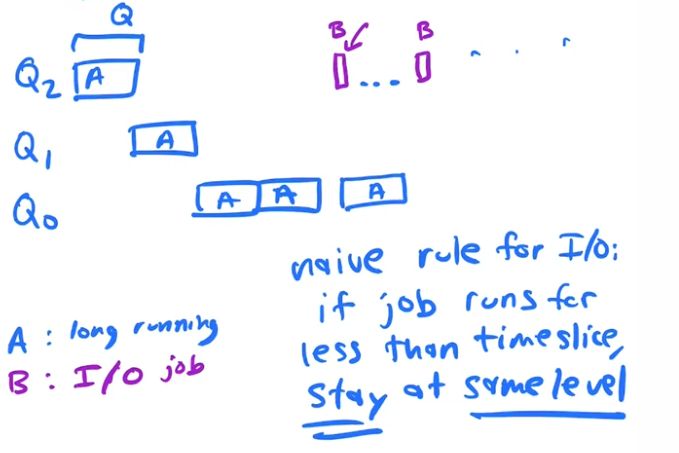
Theres is a problem with this rule
Hackers like to study schedulers, because if they understand how to take advantage of the policies they can monopolize the cpu, they are gaming the scheduler
If a time slice is 10ms. And a job only runs 9ms and then asks for i/o, our previous rule, keeps the job at the same priority level and gives it another full time slice.

Better accounting
To solve the last problem, the OS keeps track of how much time a process has used up, and once it has used up a full quantum(timeslice) of compute it gets moved down to the next priority q
It stays at the same priority until it has used a full quantum of compute
Paramaters for Multi Level Feedback Queue
- N = number of queues
- Q = quantum length, you can also have different timeslices assigned for each queue. The lower priority queues will have longer quantums
- T = learing reset interval(move jobs back to top level)
To configure your scheduler you have to adjust these paramaters. Many systems have configurable schedulers.
There is no known solution for the correct paramaters, you can try machine learning!