One of the roles of the OS is to manage physical memory
In the systems we have been discussing there are 2 levels of memory management going on
one level is inside the virtual address space of every process. The heap needs to be managed for every process. Processes calll malloc and free to allocate the memory for the heap. The stack also needs to be managed, it is managed by the compiler tool chain
The second level memory management is the Operating System managing the physical memory
The OS and physical memory
We have discussed the Mechanisms and Policy of how Operating Systems virtualize CPU's.
We are now onto an important aspect of virtualization that we have been glossing over, Virtual Memory.
The idea of virtualization in the OS is to make it seem like there are many copies of something that exist but is only an illusion. There is only one block(RAM) of physical memory on a system.
By vitalizing memory the OS make each process believe that they have an entire address space to themselves.
Process State
Programs that have been activated in a computer system are called processes. We can, because of virtualization run many processes seemingly simultaneously
An activated process has resources assigned to it, that is the CPU and RAM, the STATE OF THE REGISTERS and the STATE OF THE MEMORY within it's ADDRESS SPACE is, at any given time is the STATE OF THE PROCESS
When we say CPU virtualization we are talking about the mechanisms that enable swapping, the states of the registers for their corresponding process, on and off a CPU.
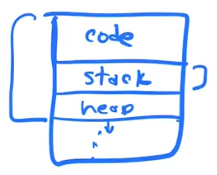
VIRTUAL ADDRESS SPACE
Each Process has a certain number of bytes that it can access. Each bytes is addressable by a number. That number(address) is from 0 to the total number of bytes in the address space - 1.
This set of addresses(numbers) is called the VIRTUAL ADDRESS SPACE of the process.
The VIRTUAL ADDRESS SPACE of a process is segmented into 4 sections
- Stack
- Heap
- globals
- code
OS Goals for Memory
There are 3 goals of the OS. They are to provide the following ABSTRACTIONS for every PROCESSES MEMORY SPACE. It wants a process to think that it has
- A LARGE AMOUNT OF MEMORY
- A PRIVATE and PROTECTED MEMORY
- A EFFICIENT MEMORY
Since addressing of bytes occurs using CPU registers, if a CPU is 64 bit, then it will have access to 2^64 different addresses. That is address 0 to address 2^64 - 1. If it is 32bit it will have access to 2^32 different addresses
Why do we want the OS to provide an abstraction to the processes that make them believe that they have a very large memory?
A small address space makes it harder to program! If a programmer has to think about running out of memory all the time and manually copying things from memory to the hard disk and back, it makes it harder to program. If the programmer has what appears to be as almost an unlimited address space, like in 64 bit machines. Their cognitive load will decrease dramatically.
By Providing an abstraction of a large address space we are making programmers jobs easier. Remember that EASE OF USE was one of the first principals of making an operating system.
Protected Memory
We want to have a protected memory
Given Process1, Process2, and a kernel all using the physical memory, we must not let p1 read from or write to p2's memory and vice a versa
We must not let p1 or p2 read or write to kernel memory
Efficient Memory
direct execution in memory terms means that when we execute , loads from memory to registers, stores from registers to memory, instruction fetches, they are all done by the CPU directly without OS involvement.
We are building an illusion of a large private virtual memory, BUT WE WANT THE CPU TO MOST OF THE WORK.
IF every time we did a load or store we jumped into the kernel code, it would slow the system down to a crawl
So we need to provide some sort of Limited Direct Execution for memory operations as well as cpu..
MECHANISMS
What mechanism are we going to use to accomplish our goals?
Just like in CPU virtualization, when we are virtualizing Memory we need support from the hardware as well as the OS.
When do Memory Accesses Occur?
Memory access is happening constantly in the following ways.
- Instruction Fetches
In memory we store instructions and data. Our Architecture says, First fetch an instruction from memory then operate on data that is also in memory or registers
- Explicit Load from memory into CPU(registers)
- Explicit Store from CPU(registrars) back to memory
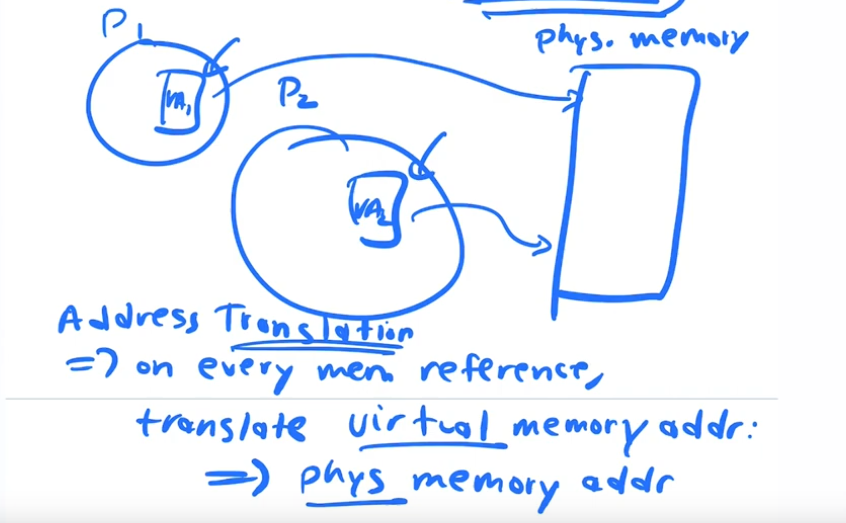
Address Translation
How does the OS interpose some address control over memory access operations?
On every single memory access a translation occurs from virtual memory of a process to the physical memory
There are different techniques for implementing address translation
Every address that you see in a running program is ALWAYS a virtual address, you never really know what the physical address is
Memory Management Unit
For Address Translation We get our hardware support form the CPU in the form of a MEMORY MANAGEMENT UNIT aka mmu
The mmu is built into the cpu and will handle all address translation for the OS. Whenever there is any virtual memory reference that comes out of a running program. The MMU, inside the cpu, will make the translation to the physical address.
The mmu is designed differently depending on what ADDRESS translation algorithm we are implementing.
let's look at an early simple address translation algorithm call dynamic relocation or base and bound
Mechanism 1, Base and Bound aka Dynamic relocation
P1 and P2 each have virtual address spaces small enough, such that, both can fit simultaneously into different parts of real physical memory.
for this basic address translation technique the MMU is just made of 2 registers. One register is called the BASE Register and one register is called the BOUND register.
The BASE register holds the ADDRESS of PHYSICAL MEMORY where the current running process starts. The virtual address acts as an offset. So if the virtual address requested is address 0. Then the physical address would be whatever is in the base register
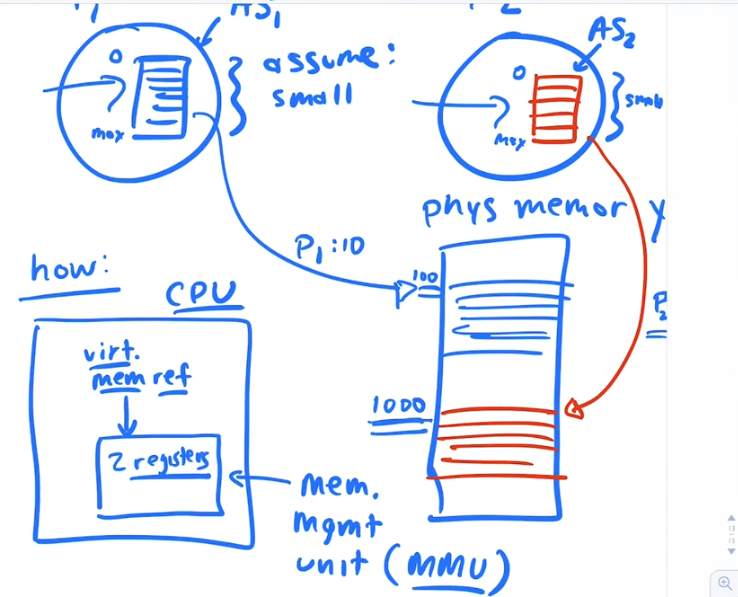
In the Base and Bound Mechanisme to get the physical address, the mmu takes the Address in the Base register, which is a physical address and adds the virtual address to it.
You can think of the virtual address as an offset in this case

What about the bounds register?
The base is for translation
The bounds is for protection, It defines the boundary of the physical address space.
We use base + virtual address to find physical address, The BOUNDS register keeps the total size of memory allocated for a given process permission. Every Address translation goes thru a 2 parts
- 1. Translation: VA + BASE
- 2 check: VA + BASE add < BASE + BOUNDS if this fails HW raises an illegal mem access exception: OS usually kills the process
Pro's
- Fast
- Simple
Con's
Every single address reference instruction needs to undergo address translation. The hardware automatically calculates the physical address from the virtual address and base registers, hardware also checks the calculated address is within the bounds .
When does the kernel software get involved.
Fragmentation
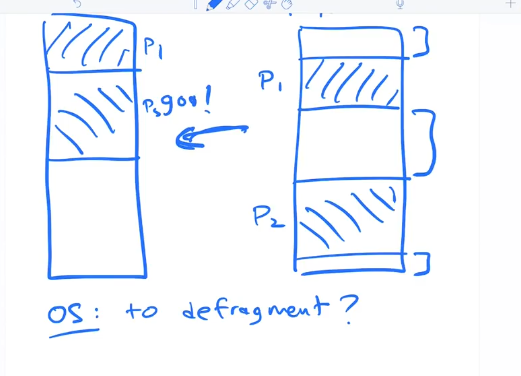
To Defragment memory the OS needs to stop the processes while it rearranges the physical memory and resets the base and bounds
- Stop the processes
- Decide where to remap physical memory
- Do a carefule non destructive copy from old to new area of physical mem
- change base register to new value
- make processes runnable again so the scheduler can get back to work
Defragmentation is costly
Dynamic Relocation is not flexible
The ideal process memory configuration is one that allows the heap and stack to grow indepenedently of one another
Dyanamic relocation sets aside a chunk of physical memory for a process. So all the space that a heap and stack may grow into is already allocated for the process and may never be used. There is only base and bounds register so no way to account for undused spacse on the inside of the process.
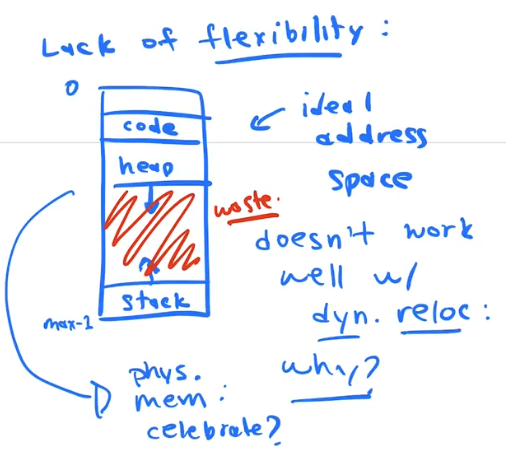
base and bounds/dynamic relocation forces us into an inflexible memory layout. If we wnat to save memory, we are forced to use a small fix sized stack and put the heap on the outside in case we need to grow the process memory at runtime
This is a less flexible memory layout
We want the more flexible layout as shown in previous slide
Reminder: address translation happens every single memory access. That is every fetch, every load or every store, in order to provide the illusion of a large effecient, and private address space for user processess
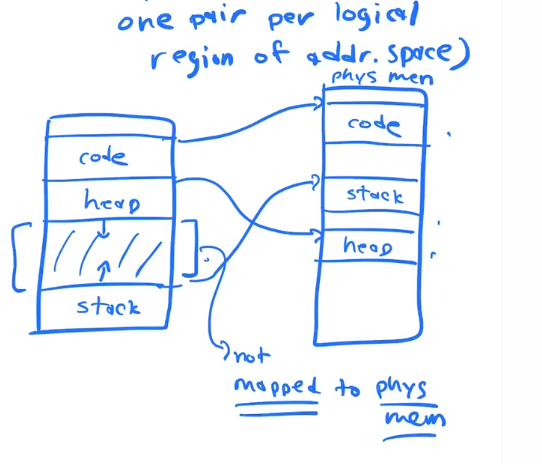
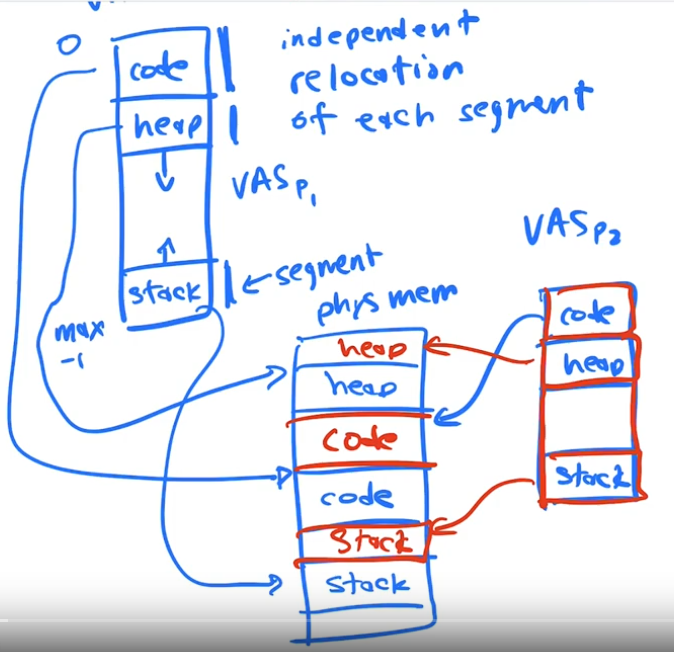
Mechanism2: Segmentation
Segmentation is a generalization of the dynamic relocation.
It uses multiple base and bounds registers per process
It has one base and pair bound per logical region of the process address space
It allows us to relocate different parts of a single processes virtual address space into non contiguous portions of physical memory
- No Internal waste
- still have defragmentation
- still have to defrag
segementation pros
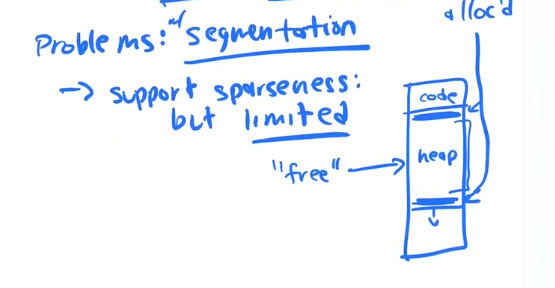
Segmentation allows us more flexibility, we no longer have to map the memory beteween the stack and heap, this allows us more flexibility than base and bounds because we do not have to reserve the space and because we do not have allocate one block of congiguous memory from top to bottom for a process.
This is the concept of a "sparse" address space.
segementation con 1
The heap segement that is allocated to your process still may not be used effeciently, and we may end up with the same problem as dynamic relocation accept just within the heap segement itself, and we end up with wasted space.
segmentation con 2
a process my request additional memory and the physical memory may have experienced external fragmentation, that is, fragementation happens outside of our mapped segments. We end up with little chunks(maybe too little to be of use) of free space between our all the different segments from all the processes, this also requires defragmention or compaction which is expensive.
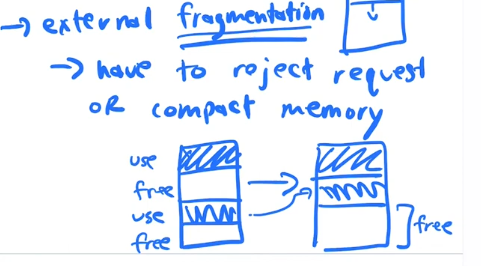
Any time you are managing a large chunk of memory and doling it in different sizes to the various applications, stack, heap, code segments all variable sizes we get this external fragmentation problem.
Mechanism3: Paging
This is our 3rd mechanism for managing address transalation, or the mapping of virtual memory space onto physical memory. This concept has been aoru
The potential drawbacks of paging are
- Can be Slow
- Can be a memory hog
Reminder:: address translation happens every single memory access. That is every fetch, every load or every store, in order to provide the illusion of a large effecient, and private address space for user processess
Pages
Divide up the Virtual address space and the physical memory into FIXED SIZE UNITS called which we call PAGES usually 4kb, 4096 bytesx
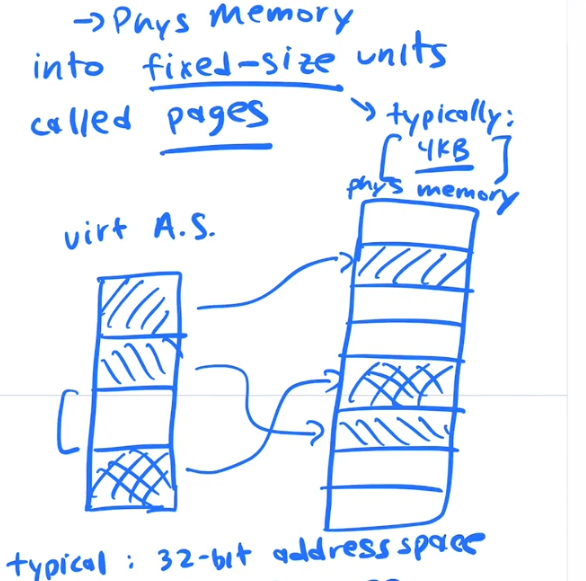
How many pages are in a typical memory?
If you have a 32 bit address space that is 2^32 addresses, that is 4gb of addresses. If you break that into 4kb pages that is 2^12 you get 2^20 pages. Which is 1mb of pages, that aprox 1 million pages.
Pages and Frames
On the virutal memory side we call each 4k chunk a PAGE, and each page is numbered 0,1,2,3....etc.
On the physical memory side we call each 4k chunk a FRAME and each fram is numbered 0,1,2,3....etc.
Page Numbers <= get mapped on to => Frame Numbers
The OS maps PAGES to FRAMES
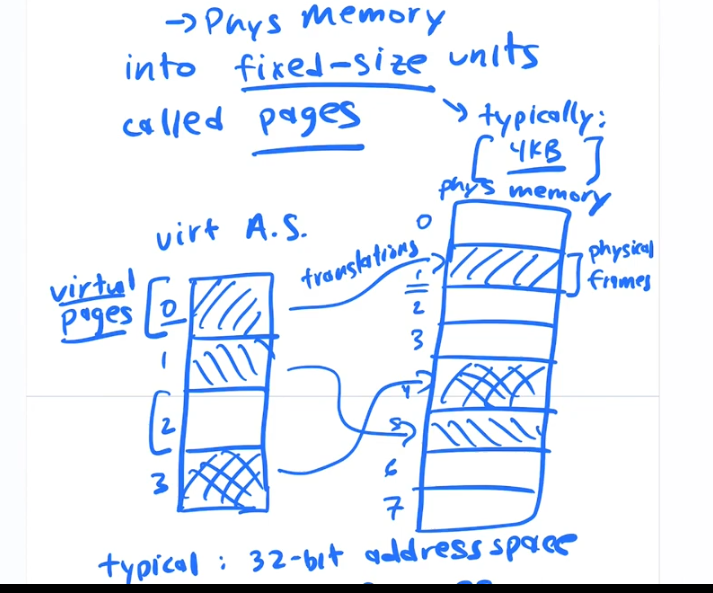
For each process there is alot of information to track. Each process may have 1 Million pages to track. So instead of base and bounds registers the translation information is stored in memory, it takes alot of space and it is slower to access.
Virtual Address encoding
If you have a 32 bit viruatl address space(2^32), and each page is 4kb(2^12) that will give you 1mb 2^20 number of pages.
The OS needs to keep a table in memory, called a PAGE TABLE, where you lookup a PAGE NUMBER and get the corresponding FRAME number in physical space
remember a PAGE is in virtual address space and a FRAME is in Physical Space
If you are using a 32 bit system you don't need all 32bits 2^32 to reference 2^20 pages
You just use the top 20bits of the Virtual address to use in the PAGE TABLE. You input the top 20 bits from the virtual addrss and you get out a 20 bit frame address
the remainng 12 bits of the 32bit virtual address acts as an offest within each PAGE or FRAME
You can access all 4096 bytes within each page or frame with 12 bits.
Page Tables
Page table is just a data structure in memory.
Each process gets their own page table
There are various data structures that can be used for page tables, and which of these used may be dictated by the hardware.
Linear Page table
We can store a page table in an array. A page table stored in an array is called a linear page table
EVERY PROCESS gets a page table so if there are 100 processes active there will be 100 Arrays
In a page table array there is one ENTRY per page
In a 32 bit system with 4kb pages we would need a 1MB array 1 index for each VIRTUAL PAGE NUMBER. Each location in the array is called a PAGE TABLE ENTRY. Each PAGE TABLE ENTRY is indexed by the top 20bits of the Virtual Address. The top 20 bits is called the VIRTUAL PAGE NUMBER. In A linear Page table the VIRTUAL PAGE NUMBER is and index of a PAGE TABLE ENTRY, the value stored(the contents)in the PAGE TABLE ENTRY is the PHYSICAL FRAME NUMBER.
Managing Page status
If you have VPN that is not in use, We need a way to trigger an exception if your program tries to access the memory on that page.

Extra bits in the page table
Every (PAGE TABLE ENTRY) in the array stores the PFN (PHYSICAL FRAME NUMBER) that a given VPN (VIRUTAL PAGE NUMBER) is mapped to. But we also store status bits in that entry that specify if the pages is VALID for access
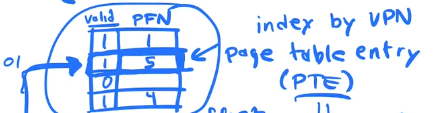
Unmapped Pages
Some or many pages in our VAS may be unused.
Page Table entires in the PAGE TABLE have feature bits that specify permissions and validity.
Pages in our VAS that are not in use, are not MAPPED to any physical memory, their PTE valid bits in the PAGE TABLE are set to NOT VALID
Limitied Direct Address Translation
We are still building a limited direct execution model
It would be too slow for the OS to be involved with address translation
Given a Page table stored in physical ram, What does the hardware need to know to do a translation for us?
- Location of the page table
- Page Size
- Addres Size
- Structure of a Page Table Entry
Page Table Base Register (PTBR)
Each CPU has a register on it where it stores the physical address of the current running processes PAGE TABLE. The PTBR changes on every context switch.
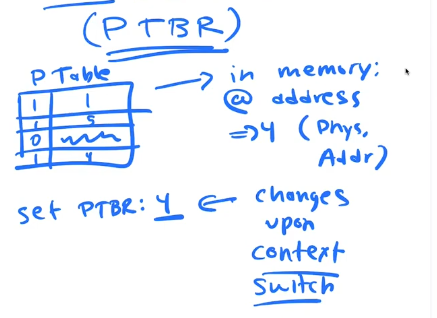
The Page table is sitting in physical memory, when an instruction is executed that requires memory access, the cpu need to do the translation. To do the translation the CPU needs to calculate the physical location of the Page table entry in relation to the PTBR.
PTBR + VPN(Virtual Page Number) * size of Page Table Entry
The translation process
When doing any memory access
- Calculate the physica location of the PTE using
PTBR + VPN(Virtual Page Number from Virtual Address) * size of Page Table Entry - combine the Physcial frame number(PFN),that was found in the PTE, with the offset from the orignal VA(virtual address) to FORM the address of the physical location for the requested data
- load, store,or fetch that data
PTBR switching
PTBR can only be changed using a priveleged instruction
The OS must save and restore PTBR in a processes process table on context switch
COST of Double memory access
One The consequences of PAGING address translation mechanism is Every memory access in your program, actually requires at least 2 PHYSICAL memory accesses. One for the transalation and on once the actual data load.
GOING TO MEMORY IS SLOW
Cost of large page tables
If every PTE is 4 bytes, and there are 1mb pages, then each PAGE TABLE is 4MB. If you have 1000 processes running that is 1000 page tables. that is 4gb of physical memory used up just on page tables. That is too much.
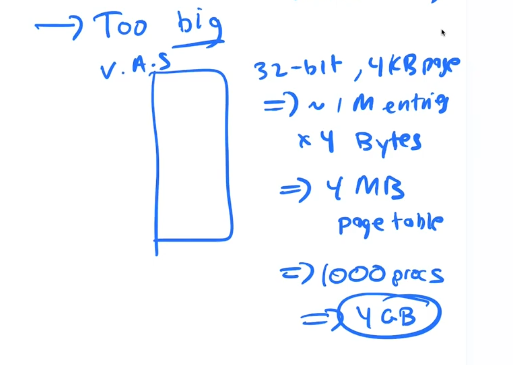
How Many 4kb pages are used in the following code
Not including the frames used for the page table
// you have an array of a[.....] of integers
int sum = 0;
int i;
for (i = 0; i < 2048; i++)
sum += a[i];
The Too Slow Problem
In PAGING Every memory operation requires two memory accesses
The first time we access memory is to get the PTE to be used in Adress translation
The second time is to get the actual bytes requested
That means it takes twice as much time as dynamic relocation or segmentation
Cache
One of the basic principles of building fast hardware is building fast memory within the cpu called cache
This memory is not as fast as registers but it is larger than the registers and much faster than ram
Ram is located far away from the cpu that's why it's slow
Cache is built into the cpu, that's why it's fast, but much smaller than ram
If we need to accesss some memory very frequently we can cache that thing inside of the CPU. We store copies of the memory in the cache on the CPU
So to alleviate the PAGING double access bottle neck we can store copies of part of a processes Page Table in the cache
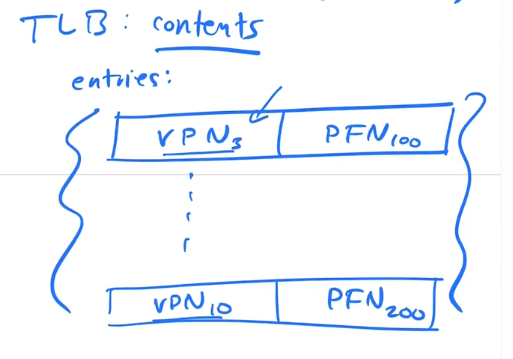
Translation Lookaside Buffer (TLB)
Cache is a smaller and faster memory on the CPU
We store a copy of parts of aprocesses Page Table in cache. We call this part of cache the TLB
This is a cache used specifically for Address translation
The TLB cannot store all 1million Entries from a Page Table it stores in the 10's to 100's of entry range worth of PTE's
TLB hit

TLB miss
The previous image shows a TLB hit.
If the VPN's PTE is not in the TLB it is a miss, so the cpu get the PTE from ram and copies it to the TLB cache.
After the copy to Cache the cpu retries the original instruction and gets a hit and contiues the translation process and instruction execution.
Cache locality principals
The Caches mechanism is that if you have a hit then you don't need to do any further memory access.
if you have MISS then you go get item from memory and load it into the cache.
The idea is that if you access something you are likely to access things near by, SPATIAL LOCALITY
and If you acesss something you are likely to access it again TEMPORAL LOCALITY
Understanding cache and how it works is one of the keys to writing fast effecient programs
If you are in a loop accessing an array, that array is layed out sequentially in memory, So multiple array entries will be on a sinlge page, by copying the PTE for that VPN into the TLB on the first miss, it guarantees that the rest of accesses will be hits
There are also caches for instruction and data, that the OS really has nothing to do with but understanding how they work will make you a better programmer.
The TLB entry stores the VPN and the PFN.
There is also a bit to indicate wether the tlb entry is valid for the current process. On every context switch, all these bits get set to INVALID. This is akin to flushing the TLB.
Some TLB are designed with extra bits to store Process ID, so a flush is not necessary.
software managed TLB
The mgmt of hits and missies, as we well as managing where page tables are loaded, how big they are, etc.. adds alot of complexity to the hardware.
It also prevents any innovation in PAGE TABLE mgmt, because all the specifications have already been set by the hardware and cannot be changed
So we came up with the idea of A software managed TLB
The idea is, If there is a TLB hit everything stays in the Hardware
We expect lots of hits because Of spatial locality and temporal locality so we want things to be fast and stay in the hardware.
TLB miss excpetion
But we created a new interupt, an exception that occurs when we miss.
Instead of the hardware loading the tlb with the missing address, the OS has a trap handler that
- Consults the page table and finds the PTE
- Updates the TLB with the entry using a priveleged instruction
- And returns from the trap
The hardware retries execution on return from trap. which leads to a hit.
Benefits of Software managed tlb
NOTICE that in this scenario, The hardware only looks at the TLB it does not need to know any details of the PAGE TABLE!!
The CPU no longer needs a Page Table Base Register.
This makes the hardware simpler
The OS developers now have freedom to come up with better page table design
Page Table review
Two more problems of linear page tables
The speed problem we solved by adding a TLB cache to the hardware
But we still have to address the followin two concerns
- Linear page tables are too big.
- Process uses more space then whats available in ram
If we have unused pages in our VAS, why do we need to keep entries for them in a Page Table? It is a giant waste of space
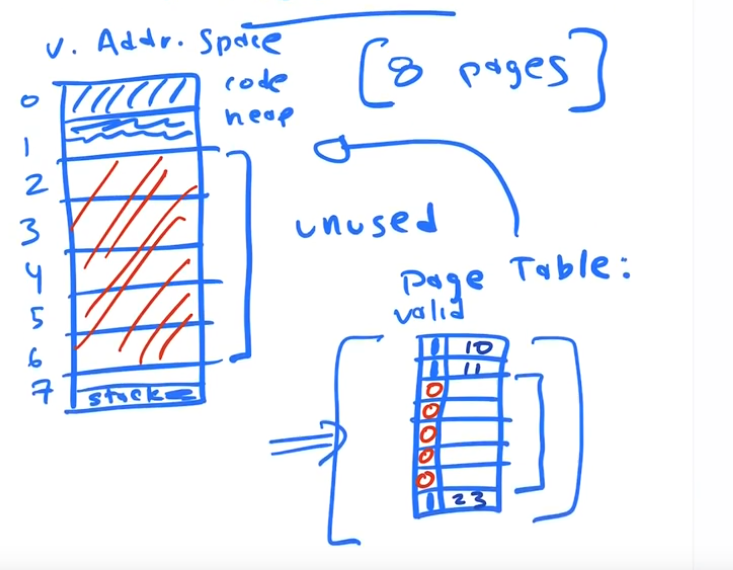
A process may be only using 3 or 4 pages of it's address space, yet it still has a PAGE TABbLE with millions of entries.
This is a giant waste of space
How can we make page tables smaller?
We need to build a more effecient data structure for our page table
What if we just make the page size bigger?
If we make each bigger, we will need less pages and thus we can have a smaller page table array.
The problem with bigger page tables is they lead to fragmentation within each page
Multi Level Page Table
To solve the problem of page tables taking up too much space in memory we divide the page table itself up into pages.
A page table is just a very large array. So we are diving that array up into pages
to make it easier for this discussion lets use the word chapter instead of page to describe how we divide up a page table
We said previously that a single processes page table in a 32 bit address space given 4kb pages, would force us to have an array with 2^20 entries. Each index of the array corresponds to a page number. When we derefernce an index we get the 20 bit physical frame number, which is the nth byte of physical memory.
The page table array is also sitting in physical memory.
Lets divide up that array into 4kb chapters, so every 4kb from Array[0] to Array[n] we will call a chapter.
How many chapters will we have?
our array is 2^20 different enteries. each entry is about 4 bytes, so our array is 2^22 bytes long.
We are dividing 2^22 bytes into 4kb(2^12) chapters. So we need to have 2^10 chapters.
LETS MAKE A TABLE OF CONTENTS.
We will call our table of contents a directory.
We will need 2^10 entries in our directory(TABLE OF CONTENTS)
Each entry in our directory will also be 4 bytes
When we look at an entry in our directory it will give us the physical frame number of the chapter we want of the page table array. We can then look in that chapter for the page number we want to get the physical frame number for the the specific page in that chapter
If we have 2^10 entries in our directory. We can use the first 10 bits of our VA to index the directory. Each chapter has 2^10 entries in it. so we can use the next 10 bits to index the page within the chapter. and the last 12 bits of the address are the offset to the correct byte in the physical frame.
If NONE OF THE PAGES IN A GIVEN CHAPTER are being used, then we do not need that chapter in physical memory at alll!!!!!
The chapters that do not have any pages in use are marked as invalid in the directory. The entry still exists in the directory but there is no chapter in memroy allocated.
The whole design is like a old white pages phone book.
A linear page table needs to be in contiguous memory.
A multilevel page table does not.
On a TLB hit: The CPU gets the physical frame number (PFN) directly from the TLB using the virtual page number (VPN). It then combines the PFN with the page offset to form the final physical address.
On a TLB miss: The CPU walks through the multi-level page table (starting from the top level), performs the full address translation (VPN to PFN), and then stores the complete result in the TLB for future accesses. The top-level table is only used during this page table walk.
Swap space
What do we do if processes use more pages than are available in physical memory ?
Memory heirachy
Fastest to slowest| Smallest to Largest | $$$$ > $
- Cpu Registers/Caches
- Main Memory
- Solid state drives
- Mechanical Harddrives
- Tapes
We realy want everything stored very high in the pace hierarchy because it's the fastest memory. BUT, there is very little space there.
The cpu automatically controls what is in cache and what is in the registers.
What do we do when main memory fills up ?
The OS copies pages from main memory out to bigger slower storage. The OS has to decide what pages to move out and what pages to move back in.
The OS buy doing this fulfills illusion goal #1 of a very large address space.
Mechanisms
We set aside space on the disk, separted into blocks that are the same size as pages. When we read and write to harddrives, it is usually in 512 byte chunks that we call sectors. When we set aside swap space on the HD we use blocks. A 4k page will use 8 sectors as a block
- VAS => PAGES
- PAS => FRAMES
- Disk => BLOCKS
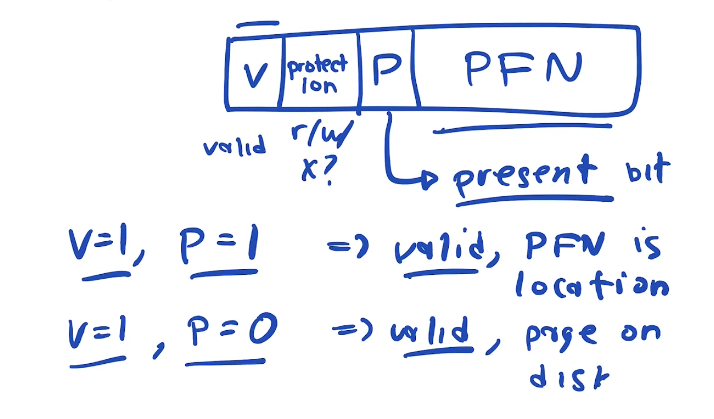
A page can be in one of three states. In our Page Table, we have bits that indicate whether
- A page is in use and valid and mapped to a PA
- A page is not in use and not mapped
- A page is in use and valid AND NOT IN MEMORY(swapped out to disk)
How do we tracked swapped pages?
In out page table we have the following bits and their indications. A page that is valid but not present we call it a PAGE FAULT
On page fault we have to load the page into memory from disk before we allow access
Swap mechanism
A page fault (page miss) happens when a process tries to read a memory location that is on a page that is active but not in main memory. That page is stored on disk. Before that page can be written into memory. A frame of memory must be written out to disk so there is enough room available for the incoming page.
Once room is available, the page on disk can be copied to Physical Memory and the page table can be updated to show the page is present and specify the frame number.
Memory reference steps
- cpu gets VA and splits it into a virtual page number and offset
- Cpu consults the TLB
ON TLB hit: CPU gets PFN from tlb, concatenate [PFN | offset] to get physical address and acesses memory
ON TLB miss: fetch PTE from memory
- Check valid bit, If invalid, segmentation fault
- Check protection rwx bits, protection fault
- check if PRESENT, if not page fault, call the OS page fault handler
- Once page fault is handled we retry the instruction.
Page fault handler
Have to find a free physical frame
if There is one then we just copy the data in to that frame from disk and update the page table
If there is not an available frame, then we have to choose a page that we are going to write out to disk to make space available
The OS Follows a "Page Replacement Policy" to choose which pages to keep and which to kick out in memory.
When the Present bit is set to 0 we can keep the address on disk in the PFN bits of the PTE
Swap Policy
When the OS needs to kick out a page, which one should it kick out?
- Least Recently Used (LRU)
- Least Frequently Used (LFU)
- Most Recently Used (MRU)
- Random
- FIFO
What is the optimal policy ?
If you had perfect knowledge of the future, the optimal policy would be to, Kick out the page that will be used furthest in the future
Some policies are Better but harder to implement
- LRU
- LFU
Some policies easier to implement
- random
- FIFO
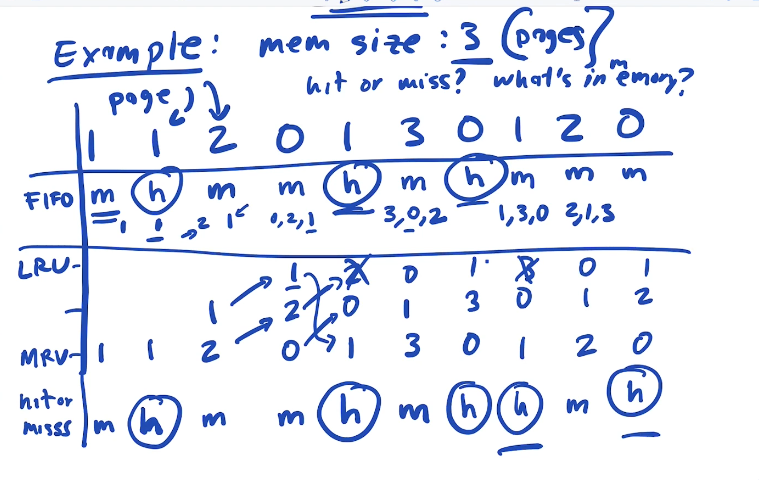
how do we implement an LRU ?
It would be too costly to mantain an additional data structure to keep track of timestamps or to keep an update an additional queue of page accesses
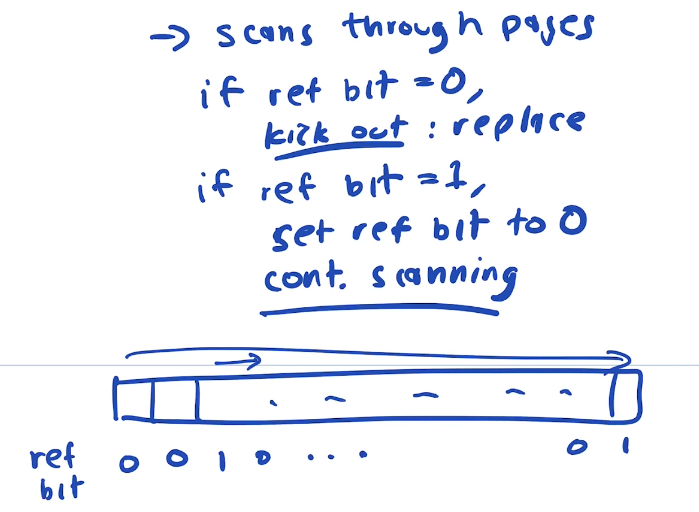
For this reason we need an LRU APPOXIMATION algorithm, that kicks out a not recently used page
LRU is implemented with an approximation algorithm developed in the 1960's
Whenver a page is accessed, the hardware sets a bit in the PTE indicating the page has been accessed. We can call this the accessed bit. When it's time to pick a page to kick out the OS scans the page table for a page where the "Accesed bit" is 0 and kicks it out. If the "referenced" bit is 1 it sets it to 0.
Swapping/PAGING is slow. Disk access maybe many 100x slower than accessing ram, if your system is experiencing slow down due to paging it almost alwasy better to add ram and to write programs that use memory effeciently!!